Annex: Tabular data analysis with pandas#
Note
If you have not yet set up Python on your computer, you can execute this tutorial in your browser via Google Colab. Click on the rocket in the top right corner and launch “Colab”. If that doesn’t work download the .ipynb file and import it in Google Colab.
Then install pandas and numpy by executing the following command in a Jupyter cell at the top of the notebook.
!pip install -q pandas numpy
Pandas is a an open source library providing tabular data structures and data analysis tools.In other words, if you can imagine the data in an Excel spreadsheet, then Pandas is the tool for the job.
Note
Documentation for this package is available at https://pandas.pydata.org/docs/.
Package Imports#
This will be our first experience with importing a package.
Usually we import pandas with the alias pd.
We might also need numpy, Python’s main library for numerical computations.
import pandas as pd
import numpy as np
Series#
A Series represents a one-dimensional array of data. It is similar to a dictionary consisting of an index and values, but has more functions.
Note
Example data on Germany’s final six nuclear power plants is from Wikipedia.
names = ["Neckarwestheim", "Isar 2", "Emsland"]
values = [1269, 1365, 1290]
s = pd.Series(values, index=names)
s
Neckarwestheim 1269
Isar 2 1365
Emsland 1290
dtype: int64
dictionary = {
"Neckarwestheim": 1269,
"Isar 2": 1365,
"Emsland": 1290,
}
s = pd.Series(dictionary)
s
Neckarwestheim 1269
Isar 2 1365
Emsland 1290
dtype: int64
Arithmetic operations can be applied to the whole pd.Series.
s**0.5
Neckarwestheim 35.623026
Isar 2 36.945906
Emsland 35.916570
dtype: float64
We can access the underlying index object if we need to:
s.index
Index(['Neckarwestheim', 'Isar 2', 'Emsland'], dtype='object')
We can get values back out using the index via the .loc attribute
s.loc["Isar 2"]
1365
Or by raw position using .iloc
s.iloc[2]
1290
We can pass a list or array to loc to get multiple rows back:
s.loc[["Neckarwestheim", "Emsland"]]
Neckarwestheim 1269
Emsland 1290
dtype: int64
DataFrame#
Series are limited to a single column. A more useful Pandas data structure is the DataFrame. A DataFrame is basically a bunch of series that share the same index.
data = {
"capacity": [1269, 1365, 1290], # MW
"type": ["PWR", "PWR", "PWR"],
"start_year": [1989, 1988, 1988],
"end_year": [np.nan, np.nan, np.nan],
}
df = pd.DataFrame(data, index=["Neckarwestheim", "Isar 2", "Emsland"])
df
| capacity | type | start_year | end_year | |
|---|---|---|---|---|
| Neckarwestheim | 1269 | PWR | 1989 | NaN |
| Isar 2 | 1365 | PWR | 1988 | NaN |
| Emsland | 1290 | PWR | 1988 | NaN |
A wide range of statistical functions are available on both Series and DataFrames.
df.min()
capacity 1269
type PWR
start_year 1988
end_year NaN
dtype: object
df.mean(numeric_only=True)
capacity 1308.000000
start_year 1988.333333
end_year NaN
dtype: float64
We can get a single column as a Series using python’s getitem syntax on the DataFrame object.
df["capacity"]
Neckarwestheim 1269
Isar 2 1365
Emsland 1290
Name: capacity, dtype: int64
Indexing works very similar to series
df.loc["Emsland"]
capacity 1290
type PWR
start_year 1988
end_year NaN
Name: Emsland, dtype: object
But we can also specify the column(s) and row(s) we want to access
df.at["Emsland", "start_year"]
1988
We can also add new columns to the DataFrame:
df["reduced_capacity"] = df.capacity * 0.8
df
| capacity | type | start_year | end_year | reduced_capacity | |
|---|---|---|---|---|---|
| Neckarwestheim | 1269 | PWR | 1989 | NaN | 1015.2 |
| Isar 2 | 1365 | PWR | 1988 | NaN | 1092.0 |
| Emsland | 1290 | PWR | 1988 | NaN | 1032.0 |
We can also remove columns or rows from a DataFrame:
Note
This operation needs to be an inplace operation to be permanent.
df.drop("reduced_capacity", axis="columns", inplace=True)
We can also drop columns with only NaN values
df.dropna(axis=1)
| capacity | type | start_year | |
|---|---|---|---|
| Neckarwestheim | 1269 | PWR | 1989 |
| Isar 2 | 1365 | PWR | 1988 |
| Emsland | 1290 | PWR | 1988 |
Or fill it up with default “fallback” data:
df.fillna(2023)
| capacity | type | start_year | end_year | |
|---|---|---|---|---|
| Neckarwestheim | 1269 | PWR | 1989 | 2023.0 |
| Isar 2 | 1365 | PWR | 1988 | 2023.0 |
| Emsland | 1290 | PWR | 1988 | 2023.0 |
Sorting Data#
We can also sort the entries in dataframes, e.g. alphabetically by index or numerically by column values
df.sort_index()
| capacity | type | start_year | end_year | |
|---|---|---|---|---|
| Emsland | 1290 | PWR | 1988 | NaN |
| Isar 2 | 1365 | PWR | 1988 | NaN |
| Neckarwestheim | 1269 | PWR | 1989 | NaN |
df.sort_values(by="capacity", ascending=False)
| capacity | type | start_year | end_year | |
|---|---|---|---|---|
| Isar 2 | 1365 | PWR | 1988 | NaN |
| Emsland | 1290 | PWR | 1988 | NaN |
| Neckarwestheim | 1269 | PWR | 1989 | NaN |
Filtering Data#
We can also filter a DataFrame using a boolean series obtained from a condition. This is very useful to build subsets of the DataFrame.
df.capacity > 1300
Neckarwestheim False
Isar 2 True
Emsland False
Name: capacity, dtype: bool
df[df.capacity > 1300]
| capacity | type | start_year | end_year | |
|---|---|---|---|---|
| Isar 2 | 1365 | PWR | 1988 | NaN |
We can also combine multiple conditions, but we need to wrap the conditions with brackets!
df[(df.capacity > 1300) & (df.start_year >= 1988)]
| capacity | type | start_year | end_year | |
|---|---|---|---|---|
| Isar 2 | 1365 | PWR | 1988 | NaN |
Or we make SQL-like queries:
df.query("start_year == 1988")
| capacity | type | start_year | end_year | |
|---|---|---|---|---|
| Isar 2 | 1365 | PWR | 1988 | NaN |
| Emsland | 1290 | PWR | 1988 | NaN |
threshold = 1300
df.query("start_year == 1988 and capacity > @threshold")
| capacity | type | start_year | end_year | |
|---|---|---|---|---|
| Isar 2 | 1365 | PWR | 1988 | NaN |
Modifying Values#
In many cases, we want to modify values in a dataframe based on some rule. To modify values, we need to use .loc or .iloc
df.loc["Isar 2", "capacity"] = 1366
df
| capacity | type | start_year | end_year | |
|---|---|---|---|---|
| Neckarwestheim | 1269 | PWR | 1989 | NaN |
| Isar 2 | 1366 | PWR | 1988 | NaN |
| Emsland | 1290 | PWR | 1988 | NaN |
Sometimes it can be useful to rename columns:
df.rename(columns=dict(type="reactor"))
| capacity | reactor | start_year | end_year | |
|---|---|---|---|---|
| Neckarwestheim | 1269 | PWR | 1989 | NaN |
| Isar 2 | 1366 | PWR | 1988 | NaN |
| Emsland | 1290 | PWR | 1988 | NaN |
Sometimes it can be useful to replace values:
df.replace({"PWR": "Pressurized water reactor"})
| capacity | type | start_year | end_year | |
|---|---|---|---|---|
| Neckarwestheim | 1269 | Pressurized water reactor | 1989 | NaN |
| Isar 2 | 1366 | Pressurized water reactor | 1988 | NaN |
| Emsland | 1290 | Pressurized water reactor | 1988 | NaN |
Time Series#
Time indexes are great when handling time-dependent data.
Let’s first read some time series data, using the pd.read_csv() function, which takes a local file path ora link to an online resource.
The example data hourly time series for Germany in 2015 for:
electricity demand from OPSD in GW
onshore wind capacity factors from renewables.ninja in per-unit of installed capacity
offshore wind capacity factors from renewables.ninja in per-unit of installed capacity
solar PV capacity factors from renewables.ninja in per-unit of installed capacity
electricity day-ahead spot market prices in €/MWh from EPEX Spot zone DE/AT/LU retrieved via SMARD platform
url = (
"https://tubcloud.tu-berlin.de/s/pKttFadrbTKSJKF/download/time-series-lecture-2.csv"
)
ts = pd.read_csv(url, index_col=0, parse_dates=True)
ts.head()
| load | onwind | offwind | solar | prices | |
|---|---|---|---|---|---|
| 2015-01-01 00:00:00 | 41.151 | 0.1566 | 0.7030 | 0.0 | NaN |
| 2015-01-01 01:00:00 | 40.135 | 0.1659 | 0.6875 | 0.0 | NaN |
| 2015-01-01 02:00:00 | 39.106 | 0.1746 | 0.6535 | 0.0 | NaN |
| 2015-01-01 03:00:00 | 38.765 | 0.1745 | 0.6803 | 0.0 | NaN |
| 2015-01-01 04:00:00 | 38.941 | 0.1826 | 0.7272 | 0.0 | NaN |
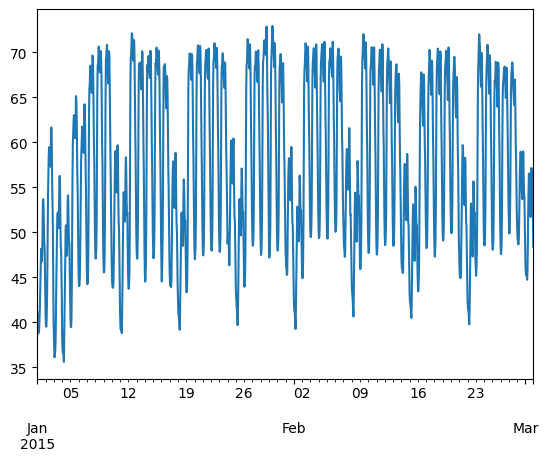
We can use Python’s slicing notation inside .loc to select a date range, and then use the built-in plotting feature of Pandas:
ts.loc["2015-01-01":"2015-03-01", "load"].plot()
<Axes: >
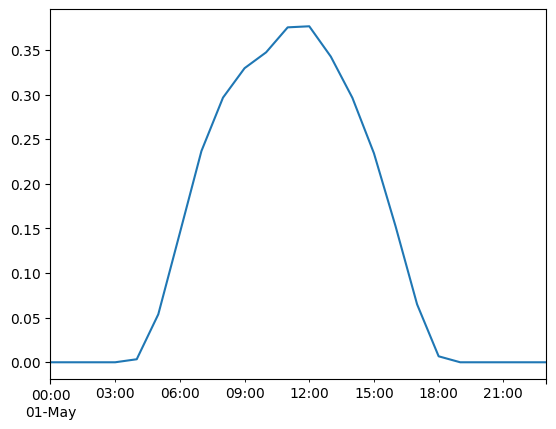
ts.loc["2015-05-01", "solar"].plot()
<Axes: >
A common operation is to change the resolution of a dataset by resampling in time, which Pandas exposes through the resample function.
Note
The resample periods are specified using pandas offset index syntax.
ts["onwind"].resample("ME").mean().plot()
<Axes: >
Groupby Functionality#
DataFrame objects have a groupby method. The simplest way to think about it is that you pass another series, whose values are used to split the original object into different groups.
Here’s an example which retrieves the total generation capacity per country:
fn = "https://raw.githubusercontent.com/PyPSA/powerplantmatching/master/powerplants.csv"
df = pd.read_csv(fn, index_col=0)
df.iloc[:5, :10]
| Name | Fueltype | Technology | Set | Country | Capacity | Efficiency | DateIn | DateRetrofit | DateOut | |
|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||
| 0 | Brokdorf | Nuclear | Steam Turbine | PP | Germany | 1410.0 | 0.33 | 1986.0 | 1986.0 | 2021.0 |
| 1 | Kernkraftwerk Emsland | Nuclear | Steam Turbine | PP | Germany | 1336.0 | 0.33 | 1988.0 | 1988.0 | 2023.0 |
| 2 | Isar | Nuclear | Steam Turbine | PP | Germany | 1410.0 | 0.33 | 1979.0 | 1988.0 | 2023.0 |
| 3 | Gemeinschaftskernkraftwerk Neckarwestheim | Nuclear | Steam Turbine | PP | Germany | 1310.0 | 0.33 | 1976.0 | 1989.0 | 2023.0 |
| 4 | Borssele | Hard Coal | Steam Turbine | PP | Netherlands | 485.0 | NaN | 1973.0 | NaN | 2034.0 |
grouped = df.groupby("Country").Capacity.sum()
grouped.head()
Country
Albania 2370.400000
Austria 24643.200368
Belgium 21443.151009
Bosnia and Herzegovina 4827.195964
Bulgaria 15699.186363
Name: Capacity, dtype: float64
Let’s break apart this operation a bit. The workflow with groupby can be divided into three general steps:
Split: Partition the data into different groups based on some criterion.
Apply: Do some caclulation within each group, e.g. minimum, maximum, sums.
Combine: Put the results back together into a single object.

Grouping is not only possible on a single columns, but also on multiple columns. For instance,
we might want to group the capacities by country and fuel type. To achieve this, we pass a list of functions to the groupby functions.
capacities = df.groupby(["Country", "Fueltype"]).Capacity.sum()
capacities
Country Fueltype
Albania Hydro 1743.9
Other 98.0
Solar 294.5
Wind 234.0
Austria Hard Coal 1331.4
...
United Kingdom Other 55.0
Solar 11668.6
Solid Biomass 4919.0
Waste 288.9
Wind 38670.3
Name: Capacity, Length: 242, dtype: float64
By grouping by multiple attributes, our index becomes a pd.MultiIndex (a hierarchical index with multiple levels.
capacities.index[:5]
MultiIndex([('Albania', 'Hydro'),
('Albania', 'Other'),
('Albania', 'Solar'),
('Albania', 'Wind'),
('Austria', 'Hard Coal')],
names=['Country', 'Fueltype'])
We can use the .unstack function to reshape the multi-indexed pd.Series into a pd.DataFrame which has the second index level as columns.
capacities.unstack().tail().T
| Country | Spain | Sweden | Switzerland | Ukraine | United Kingdom |
|---|---|---|---|---|---|
| Fueltype | |||||
| Biogas | NaN | NaN | NaN | NaN | 31.000000 |
| Geothermal | NaN | NaN | NaN | NaN | NaN |
| Hard Coal | 11904.878478 | 291.000000 | NaN | 24474.0 | 33823.617061 |
| Hydro | 26069.861248 | 14273.686625 | 20115.0408 | 6590.0 | 4576.175000 |
| Lignite | 1831.400000 | NaN | NaN | NaN | NaN |
| Natural Gas | 28394.244000 | 2358.000000 | 55.0000 | 4687.9 | 36366.400000 |
| Nuclear | 7733.200000 | 9859.000000 | 3355.0000 | 17635.0 | 19181.000000 |
| Oil | 1854.371000 | 1685.000000 | NaN | NaN | 100.000000 |
| Other | NaN | NaN | NaN | NaN | 55.000000 |
| Solar | 36998.200000 | 281.800000 | 96.8000 | 5628.7 | 11668.600000 |
| Solid Biomass | 563.000000 | 2432.600000 | NaN | NaN | 4919.000000 |
| Waste | 388.054000 | NaN | NaN | NaN | 288.900000 |
| Wind | 34371.650000 | 16958.800000 | 55.0000 | 461.4 | 38670.300000 |
Exercises#
Task 1: Provide a list of unique fuel types included in the power plants dataset.
Show code cell content
df.Fueltype.unique()
array(['Nuclear', 'Hard Coal', 'Hydro', 'Oil', 'Lignite', 'Natural Gas',
'Solid Biomass', 'Wind', 'Other', 'Solar', 'Waste', 'Biogas',
'Geothermal'], dtype=object)
Task 2: Filter the dataset by power plants with the fuel type “Hard Coal”. How many hard coal power plants are there?
Show code cell content
coal = df.loc[df.Fueltype == "Hard Coal"]
coal
| Name | Fueltype | Technology | Set | Country | Capacity | Efficiency | DateIn | DateRetrofit | DateOut | lat | lon | Duration | Volume_Mm3 | DamHeight_m | StorageCapacity_MWh | EIC | projectID | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||||
| 4 | Borssele | Hard Coal | Steam Turbine | PP | Netherlands | 485.000000 | NaN | 1973.0 | NaN | 2034.0 | 51.433200 | 3.716000 | NaN | 0.0 | 0.0 | 0.0 | {'49W000000000054X'} | {'BEYONDCOAL': {'BEYOND-NL-2'}, 'ENTSOE': {'49... |
| 80 | Didcot | Hard Coal | CCGT | PP | United Kingdom | 1490.000000 | 0.550000 | 1970.0 | 1998.0 | 2013.0 | 51.622300 | -1.260800 | NaN | 0.0 | 0.0 | 0.0 | {'48WSTN0000DIDCBC'} | {'BEYONDCOAL': {'BEYOND-UK-22'}, 'ENTSOE': {'4... |
| 81 | Emile Huchet | Hard Coal | CCGT | PP | France | 596.493211 | NaN | 1958.0 | 2010.0 | 2022.0 | 49.152500 | 6.698100 | NaN | 0.0 | 0.0 | 0.0 | {'17W100P100P0345B', '17W100P100P0344D'} | {'BEYONDCOAL': {'BEYOND-FR-67'}, 'ENTSOE': {'1... |
| 82 | Amercoeur | Hard Coal | CCGT | PP | Belgium | 451.000000 | 0.187765 | 1968.0 | NaN | 2009.0 | 50.431000 | 4.395500 | NaN | 0.0 | 0.0 | 0.0 | {'22WAMERCO000010Y'} | {'BEYONDCOAL': {'BEYOND-BE-27'}, 'ENTSOE': {'2... |
| 83 | Timelkam | Hard Coal | CCGT | CHP | Austria | 400.000000 | 0.590000 | 1962.0 | 2008.0 | 2008.0 | 48.010800 | 13.589100 | NaN | 0.0 | 0.0 | 0.0 | {'14WENERGIE--WT02'} | {'BEYONDCOAL': {'BEYOND-AT-9'}, 'ENTSOE': {'14... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 29782 | St | Hard Coal | NaN | CHP | Germany | 21.645000 | NaN | 1982.0 | NaN | NaN | 49.976593 | 9.068953 | NaN | 0.0 | 0.0 | 0.0 | {nan} | {'MASTR': {'MASTR-SEE971943692655'}} |
| 29807 | Uer | Hard Coal | NaN | CHP | Germany | 15.200000 | NaN | 1964.0 | NaN | NaN | 51.368132 | 6.662350 | NaN | 0.0 | 0.0 | 0.0 | {nan} | {'MASTR': {'MASTR-SEE988421065542'}} |
| 29816 | Walheim | Hard Coal | NaN | PP | Germany | 244.000000 | NaN | 1964.0 | NaN | NaN | 49.017585 | 9.157690 | NaN | 0.0 | 0.0 | 0.0 | {nan, nan} | {'MASTR': {'MASTR-SEE964114029633', 'MASTR-SEE... |
| 29833 | Wd Ffw | Hard Coal | NaN | CHP | Germany | 123.000000 | NaN | 1990.0 | NaN | NaN | 50.099000 | 8.653000 | NaN | 0.0 | 0.0 | 0.0 | {nan, nan} | {'MASTR': {'MASTR-SEE915289541482', 'MASTR-SEE... |
| 29838 | West | Hard Coal | NaN | CHP | Germany | 277.000000 | NaN | 1985.0 | NaN | NaN | 52.442456 | 10.762681 | NaN | 0.0 | 0.0 | 0.0 | {nan, nan} | {'MASTR': {'MASTR-SEE917432813484', 'MASTR-SEE... |
332 rows × 18 columns
Task 3: Identify the three largest coal power plants. In which countries are they located? When were they built?
Show code cell content
coal.loc[coal.Capacity.nlargest(3).index]
| Name | Fueltype | Technology | Set | Country | Capacity | Efficiency | DateIn | DateRetrofit | DateOut | lat | lon | Duration | Volume_Mm3 | DamHeight_m | StorageCapacity_MWh | EIC | projectID | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||||
| 249 | Kozienice | Hard Coal | Steam Turbine | PP | Poland | 3682.216205 | NaN | 1972.0 | NaN | 2042.0 | 51.6647 | 21.4667 | NaN | 0.0 | 0.0 | 0.0 | {'19W000000000095U', '19W000000000104I'} | {'BEYONDCOAL': {'BEYOND-PL-96'}, 'ENTSOE': {'1... |
| 3650 | Vuglegirska | Hard Coal | CCGT | PP | Ukraine | 3600.000000 | NaN | 1972.0 | NaN | NaN | 48.4652 | 38.2027 | NaN | 0.0 | 0.0 | 0.0 | {nan} | {'GPD': {'WRI1005107'}, 'GEO': {'GEO-43001'}} |
| 513 | Opole | Hard Coal | Steam Turbine | PP | Poland | 3071.893939 | NaN | 1993.0 | NaN | 2020.0 | 50.7518 | 17.8820 | NaN | 0.0 | 0.0 | 0.0 | {'19W0000000001292'} | {'BEYONDCOAL': {'BEYOND-PL-16'}, 'ENTSOE': {'1... |
Task 4: What is the average “DateIn” of each “Fueltype”? Which type of power plants is the oldest on average?
Show code cell content
2024 - df.groupby("Fueltype").DateIn.mean().sort_values()
Fueltype
Hard Coal 52.092593
Hydro 51.260690
Nuclear 48.214953
Lignite 47.184211
Other 31.543103
Waste 26.845588
Geothermal 23.857143
Oil 23.410138
Solid Biomass 22.516588
Natural Gas 22.089599
Wind 14.483789
Biogas 11.415730
Solar 8.584491
Name: DateIn, dtype: float64
Task 5: In the time series provided, calculate the annual average capacity factors of wind and solar.
Show code cell content
ts.mean()
load 54.736992
onwind 0.205556
offwind 0.362993
solar 0.122621
prices 31.835717
dtype: float64
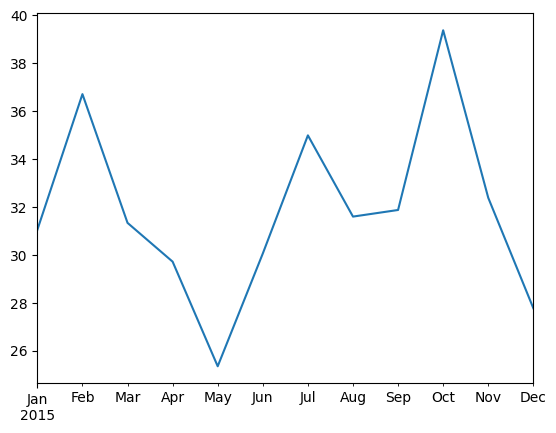
Task 6: In the time series provided, calculate and plot the monthly average electricity price.
Show code cell content
ts["prices"].resample("ME").mean().plot()
<Axes: >